Lists To Guide Standards
.
I have long felt that curated lists have great potential to help set standards in technology and in society more broadly.
We referred to this GitHub repository of AI crawlers to block when instructing bots to ignore our content at openDemocracy.
This list was created by an independent developer to fill a need. I don’t know if there are other lists like this but it’s a good and prominent one and therefore becomes an important resource.
It now helps guide which content is available to the web crawlers used by major AI models. In this way it acts as a feature of the global information landscape.
From simple lists to complex standards
Whilst this humble list popped up to serve a basic need in the developer community, it occupies a position which could have even greater impact.
On the one hand, it is just a configuration file to be borrowed by web administrators; on the other hand it is a tool that identifies web entities as being something that people should consider blocking.
This repository could be expanded with, for example, a table that includes other info about a crawler e.g. the operator’s policies on data usage, or the regularity of the bot’s visit thus its effect on site performance.
Those data points could offer a richer perspective on which bot to block, and therefore offer a more fine-grained picture of the bot landscape. That in turn could drive decisions about how bots and AI model creators actually operate.
This all requires more work to update, And as it accrues more meaning that can add responsibility and risk for the repository maintainer.
Nevertheless, it is a useful example of how important standards can develop from simple open source efforts.
Rating crawlers
What metrics would we want to rate web crawlers on? A few options include:
- Whether they respect
robots.txtfiles. - How they use the data that they scrape e.g. commercially, with citations to the source.
- How often they visit, thus how they might impact site performance.
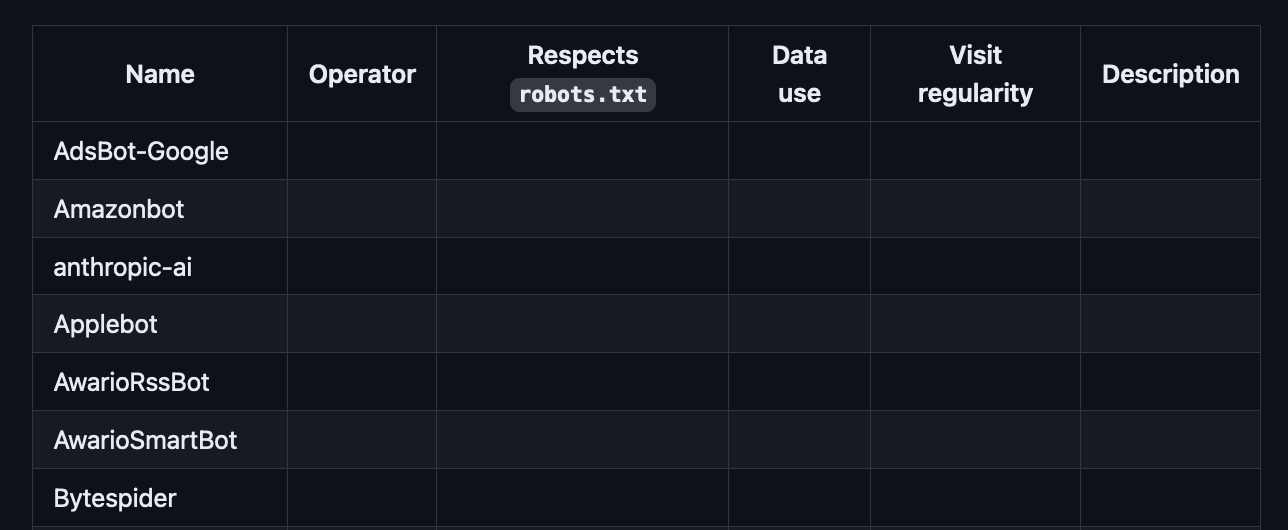 The metrics box now in the ai-robots GitHub repo.
The metrics box now in the ai-robots GitHub repo.
Not all crawlers are undesirable and this sort of data could be used by site operators to decide whether to allow a given bot.
This in turn is a reputational matter, so we would want to ensure that the data is well evidenced (and a disclaimer given on the repo to explain that evidence may not be definitive). So data submissions (probably as a pull request to the repo) should include a description of how the data point was established with a link to supporting evidence. More involved forms of data and proof may become necessarily eventually.
I have added this element to the AI robots GitHub repo in the hope that we can expand its impact.